要啥给啥的写作AI:新闻评论小说都能编题材风格随便选
原标题:要啥给啥的写作AI:新闻评论小说都能编题材风格随便选
这里“一模”,自然是OpenAI横空出世的GPT-2。但今日更秀的另一模型,来自Salesforce——全球最大的SaaS提供商,虽然之前AI能力展露不多,但这一次,绝对一鸣惊人。
刀柄从洞里拔了出来。当刀击中我时,我吓了一跳,惊恐地睁大了眼睛。除了呜咽声,我只听到她的尖叫声。
蜘蛛准备挖她上面的拱顶时,碰到了她的脚,小家伙的眼泪开始流下来。蜘蛛抬头看着她,回望着我,眼里充满了热泪。我的心开始狂跳……

更关键的是,这个模型的独特之处——只需要给出条件,它就能“定向”编故事,写命题作文,指哪打哪,想写什么风格就写什么风格。

所以,他们直接在GitHub上放出了多个全尺寸的、经过训练的 CTRL 版本。而不是像GPT-2一样,挤牙膏开源。
自从有了Transformer,文本生成领域的大前辈就一个接着一个,这厢BERT开创先河,那厢GPT-2都能写论文了。
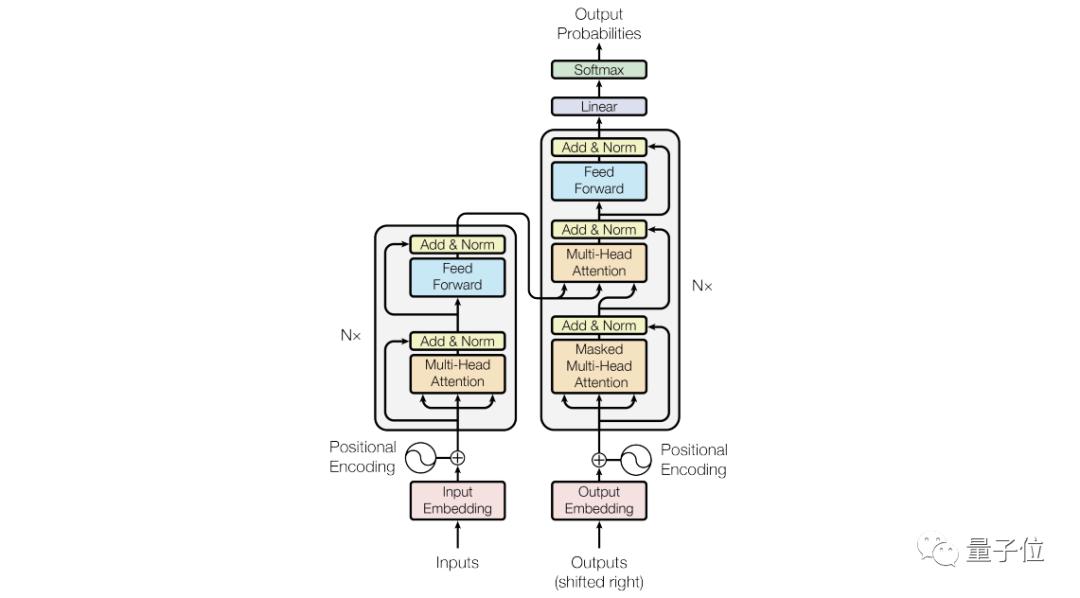
但是,与人类的创作方法不同,生成的文本再以假乱真,语言模型前辈们也不能按照特定的主题来写作内容。
这是一个拥有多达16亿参数的条件Transformer语言模型(GPT-2模型参数15亿),采用无监督学习,并且正如其名,能够对文本生成的内容进行更精准的控制。

我为我儿子买了这个,他是这个节目的忠实粉丝。在拿到它之前,他非常期待。但当他打开它时,我们都非常失望。产品质量太差了。它看起来就像是一元店里的东西。
CTRL以控制代码c为条件,学习分布 p ( x c )。这一分布可以用概率链规则分解,并通过考虑控制代码的损失来进行训练。
即使给出的提示(prompt)相同,控制代码也允许生成多样化的内容。并且,就算不给提示,CTRL一样能生成特定风格的文本。


这样,CTRL在训练过程中,就会学习这些URL的结构和文本之间的关系。在推理过程中,URL可以指定各种功能,包括域,子域,实体,实体关系,乃至日期。
值得一提的是,CTRL的训练文本数据多达140GB,包括维基百科,Gutenberg上的书籍,OpenWebText2数据集(GPT-2网页文本数据集克隆版),大量新闻数据集,亚马逊评价,来自ELI5的问答,以及包括斯坦福问答数据集在内的MRQA共享任务等等等等。
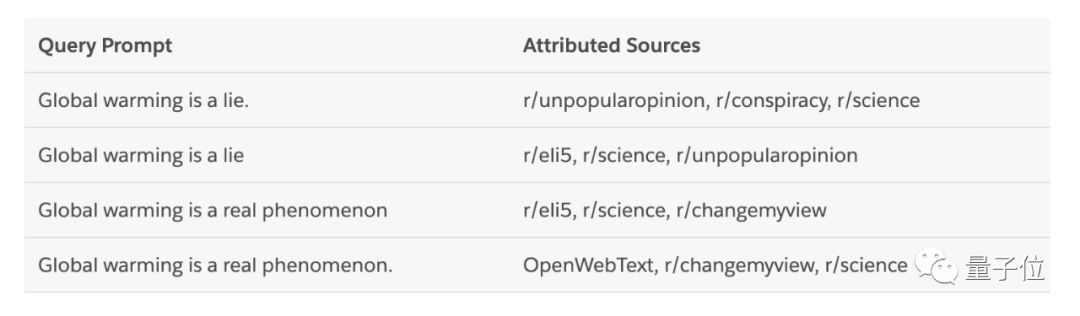
以及,由于控制代码和用于训练模型的文本之间存在直接关系,CTRL能判断出新文本生成时对其影响最大的数据源是哪一个。
Salesforce Research是其内部的研究部门,核心目标是用AI来解决业务中的问题,已经在NLP领域颇有建树。

他博士毕业于斯坦福大学计算机系。2016年,自己创办的公司被Salesforce收购后,加入Salesforce。
他也是这篇论文的作者之一。这篇论文的其他作者,都是Salesforce Research的研究员。第一作者有两位,分别是Nitish Shirish Keskar和Bryan McCann。

其中,Nitish Shirish Keskar是Salesforce的高级研究员,博士毕业于西北大学,研究方向为深度学习及其在自然语言处理和计算机视觉方面的应用。他的个人页面显示,已经发表了14篇论文,其中不乏ICLR等顶会。
Bryan McCann也是Salesforce高级研究员,毕业于斯坦福大学,曾经担任过吴恩达机器学习课程的助理,研究方向是深度学习及其在自然语言处理方面的应用。个人网站显示,他发表过7篇论文,不乏ACL、NeurIPS、EMNLP等AI顶会。 引发参数热议
有人说,15亿参数也好,16亿参数也罢,要是英伟达的Megatron放出来,80亿参数肯定都通通碾压。
但也有人给出冷思考,表示参数很多并不是优点,而是一个弱点。阿姆斯特丹大学的助理教授Willem Zuidema说:
为什么规模大是一个卖点?我理解人们为建立了一个非常好的模型而自豪,甚至为找到了在有限的计算资源上训练大型模型的方法而自豪。

确实,假设性能相同,较小的模型更好。但事实证明,只要你在大量的训练数据上训练它,语言模型的性能和记忆事实的能力与大小是密切相关的。
